 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Assessment of Generalization Performance Robustness for Deep Networks via Contrastive Examples
Jun 20, 2021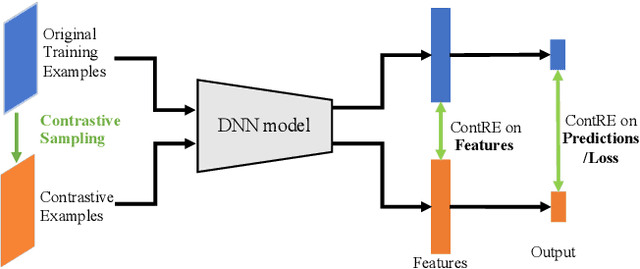
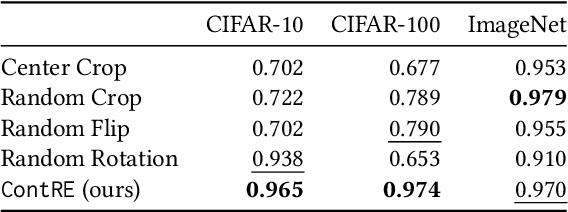
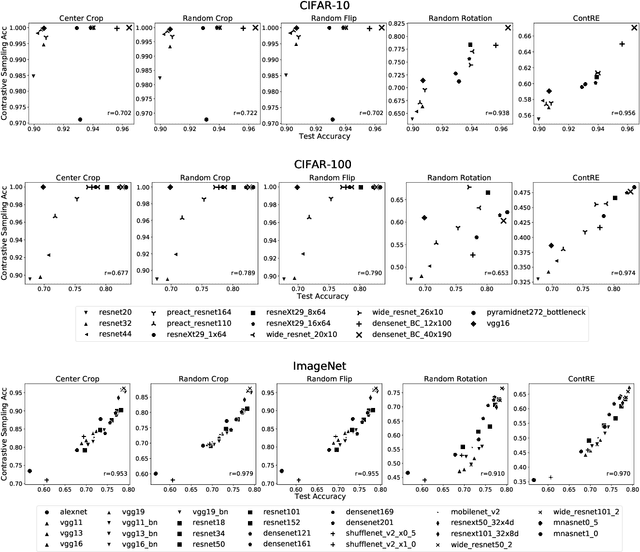
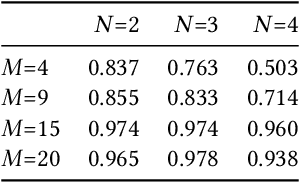
Training images with data transformations have been suggested as contrastive examples to complement the testing set for generalization performance evaluation of deep neural networks (DNNs). In this work, we propose a practical framework ContRE (The word "contre" means "against" or "versus" in French.) that uses Contrastive examples for DNN geneRalization performance Estimation. Specifically, ContRE follows the assumption in contrastive learning that robust DNN models with good generalization performance are capable of extracting a consistent set of features and making consistent predictions from the same image under varying data transformations. Incorporating with a set of randomized strategies for well-designed data transformations over the training set, ContRE adopts classification errors and Fisher ratios on the generated contrastive examples to assess and analyze the generalization performance of deep models in complement with a testing set. To show the effectiveness and the efficiency of ContRE, extensive experiments have been done using various DNN models on three open source benchmark datasets with thorough ablation studies and applicability analyses. Our experiment results confirm that (1) behaviors of deep models on contrastive examples are strongly correlated to what on the testing set, and (2) ContRE is a robust measure of generalization performance complementing to the testing set in various settings.
Interpretable Deep Learning: Interpretations, Interpretability, Trustworthiness, and Beyond
Mar 19, 2021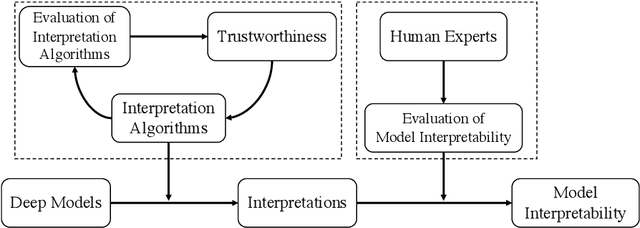
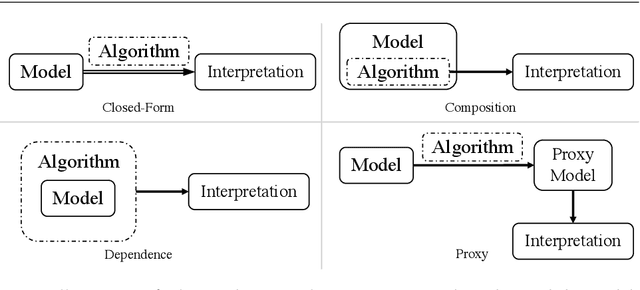
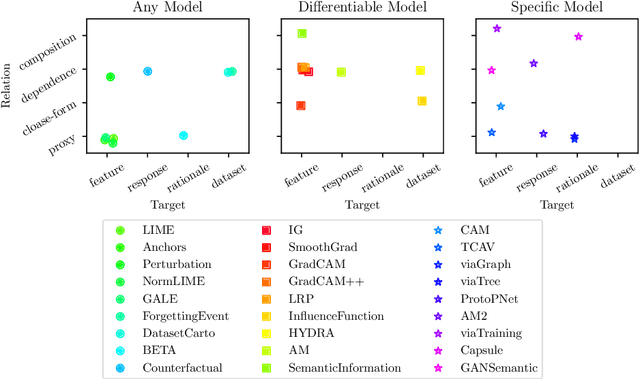

Deep neural networks have been well-known for their superb performance in handling various machine learning and artificial intelligence tasks. However, due to their over-parameterized black-box nature, it is often difficult to understand the prediction results of deep models. In recent years, many interpretation tools have been proposed to explain or reveal the ways that deep models make decisions. In this paper, we review this line of research and try to make a comprehensive survey. Specifically, we introduce and clarify two basic concepts-interpretations and interpretability-that people usually get confused. First of all, to address the research efforts in interpretations, we elaborate the design of several recent interpretation algorithms, from different perspectives, through proposing a new taxonomy. Then, to understand the results of interpretation, we also survey the performance metrics for evaluating interpretation algorithms. Further, we summarize the existing work in evaluating models' interpretability using "trustworthy" interpretation algorithms. Finally, we review and discuss the connections between deep models' interpretations and other factors, such as adversarial robustness and data augmentations, and we introduce several open-source libraries for interpretation algorithms and evaluation approaches.